

Abstract
All new mainstream microprocessors have two or more cores and relatively soon we can expect to see tens or hundreds of cores. We cannot expect the performance of each individual core to improve much further. The only way to achieve increasing performance from each new generation of chips is by dividing the work of a program across multiple processing cores. This multi-core paradigm shift has forced the software industry to change the way applications are written. To utilize the available cores to their highest potential parallel programs are needed. Similarly, legacy applications need to be re-written or parallelized so that the new multi-core hardware is exploited fully.
Converting legacy applications manually is difficult, cost and time consuming and hence there is a need for tools that can aid in the conversion of legacy sequential code to parallel code. To address this need we present the S2P+ (Serial to Parallel Plus) application, an automated code conversion tool which parallelizes legacy sequential C/C++/C#/VB.NET/Java programs for multi-core shared memory architectures typical of the modern multi-core laptop, desktop, blade server, or high performance computing (HPC) platforms.
S2P+ is suitable for use in both defense and commercial sectors. Any business with legacy code that needs optimized and innovative software to exploit multi-core, multi-threaded operating system functionality would benefit from this product.
Benefits: S2P+ will cost-effectively help automate the process of explicitly parallelizing legacy applications. This will allow legacy code to utilize modern multi-core microprocessors and speedup processing time. S2P+ will include support for a range of development languages (C/C++/C#/VB.NET/Java) in legacy applications, both unmanaged and managed code. The application will initially focus on source code to source code conversion of legacy applications coded in ‘C’ and ‘C++’.
Any business with legacy code that needs optimized and innovative software to exploit multi-core, multi-threaded operating system functionality will benefit from this product.
Key Words: parallel processing, multi-core microprocessors, multi-threaded applications, legacy software code conversion, C/C++/C#/VB.NET/Java programs, 64-bit code conversion, concurrency collections, OpenMP.
1 Problem Identification and Significance
There is a significant amount of legacy code that was designed based on older processor legacy hardware. Current legacy code is less than optimal to reuse in newer architectures since it was primarily written and implemented in a single thread single core processor environment. This software is unable to take advantage of new functionality like multi-core hardware and multi-threading software and other advanced trends in processor architecture. Furthermore, it is cost prohibitive to re-code, test and qualify software to fully utilize newer multi-core platforms.
This whitepaper introduces a software tool capable of facilitating the upgrade of existing software to exploit the benefits of multi-core processor technology and parallel processing to improve throughput and timeliness of software intensive tasks. This tool will provide the ability to analyze and transform legacy software and allow it to operate with a series of parallel simultaneous threads. Successful development of this tool will save programming time in upgrading existing legacy code extending the life span of these systems.
To address the challenges of optimizing legacy applications to take advantage of multi-core processors, we propose a multi-faceted approach. The proposal focuses on the various techniques that may be used to speed up legacy software on the Windows and Linux platforms. Recognizing that the amount of application processing enhancement using parallel coding alone might not be optimum, this proposal includes descriptions of a full range of code performance modifications including the use of existing COTS tools as well as explicit parallelization via the development of the custom S2P+ application to automate the process of serial to parallel code conversion.
This proposal takes a broad view of the problem space, which are techniques used to provide performance enhancements to legacy applications. The performance enhancements methods to improve throughput and timelines described include but are not limited to implicit and explicit parallel programming techniques. The implicit techniques represent the set of tools that will be used by the S2P+ application to automate the conversion of legacy application to take advantage of multi-core processing.
The custom application to be developed to automate the process of explicitly parallelizing legacy applications is referred to here as “S2P+”. S2P+ will include support for a range of development languages (C/C++/C#/VB.NET/Java) in legacy applications, both unmanaged and managed code. The application will initially focus on source code to source code conversion of legacy applications coded in ‘C’ and ‘C++’.
1.1.1 Development Philosophy
When converting legacy applications for higher performance, there are significant benefits in leveraging the incremental design philosophy where small changes are made, existing operationally behavior validated, and performance increases measured. Parallelism can be added incrementally until performance goals are met: i.e. the sequential program evolves into a highly parallel program. This philosophy supports the progression of code parallelism from manual techniques (human-in-the-loop, or HTL as described in paragraph 2.4.1.10), semi-automatic, to fully automatic.
1.1.2 Performance Benefit of Parallelism
When dealing with the performance benefits of parallelization of serial code, the upper bound on what can be achieved with parallel techniques is generally described by Amdahl’s Law [1]. The computer architect Gene Amdahl introduced the theory where the maximum expected improvement to an overall system when only part of the system is improved. His theory is often used in parallel computing to predict the theoretical maximum speed up using multiple processors.
Amdahl’s law predicts that the speedup of a program using multiple processors in parallel computing is limited by the time needed for the sequential fraction of the program. The law is concerned with the speedup achievable from an improvement to a computation that affects a proportion P of that computation where the improvement has a speedup of S. For example, if 30% of the computation may be the subject of a speed up, P will be 0.3; if the improvement makes the portion affected twice as fast, S will be 2. Amdahl’s law states that the overall speedup of applying the improvement will be:
Proportion of Code P = 0.3, Improvement in Speed = 2.0
1/((1-P)+P/S)=1/((1-0.3)+0.3/2)=1.176 Performance Gain
Figure 1 illustrates the Amdahl’s Law speedup curves for a range of processors available for 4 different parallel portion values. With respect to optimizing legacy code, the maximum speed up possible using parallel techniques alone will likely be bounded by Amdahl’s law, and is based on the percentage of the code base that can benefit from parallel techniques relative to code that cannot. Application codes that cannot be made parallel are routines that are often I/O intensive. For example, application code using sockets cannot scale on a multi-core/multithreaded by binding multiple threads to the same socket. Linear performance increases based on number of processors is not achievable.
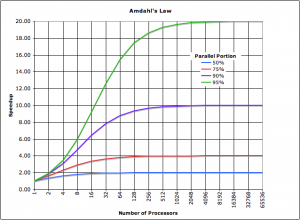
Figure 1: Amdahl’s Law Curves
2 S2P+ Solution
The design of the S2P+ solution and related framework that can be implemented are organized as follows:
- Application Decomposition –Define and produce a document containing a study of the methods for the decomposing legacy application by language, functionality, interface, etc.
- Optimization Techniques without Explicit Parallelism – Analyze relevant techniques for optimizing legacy applications without explicitly parallelizing the source code through code changes.
- Parallel Solutions – Perform a trade study of technologies for each development language evaluated forming the underlying APIs incorporated into the S2P+ application when parallelizing legacy code during the S2P+ code generation process.
- Explicit Parallelization via S2P+ – Perform system design process for the S2P+ application which inserts compiler directives or library API calls into legacy code thus facilitating parallel processing on shared memory parallel (SMP) machines.
2.1 S2P+ Workflow
The S2P+ application takes legacy source code (initially C and C++; C# and Java in the future) as input which will have multiple source and header files in various development languages. The output code is a multi-threaded parallel code using language specific parallel constructs (e.g. OpenMP, OpenMPC, Intel TBB, Cilk Plus, TPL, etc.) as described in paragraph 2.4. The S2P+ generated code is compiled into machine language using a compiler (or intermediate language for C# and Java), which executes on the operating system on the multi-core platform. Figure 2 shows the where S2P+ tool fits in the typical software development and execution model. The following is a potential workflow for the S2P+ application.

Figure 2: S2P+ Tool in Typical Software Development and Execution Model
2.2 Application Decomposition
- Prerequisite to performing a performance code conversion/generation strategy on a legacy code base is to identify and quantify the composition of the legacy application into percentages of a particular development language (e.g. C/C++/C#/VB.NET/Java)
- Functionality assigned to each development language (e.g. GUI or worker threads)
- Interfaces used between components (e.g. COM/ActiveX interfaces or DLL)
- Identifying all candidate dependent 3rd party libraries
- Listing source code modules that conceptually would benefit from parallelism
- Evaluating the complexity of the parallel models
There is no one technique or technology that applies equally to various development languages. Typical applications used in the simulation environment consist of:
- Native/unmanaged/machine code in Visual Basic 6, C and C++
- Managed code in the form of C# or VB.NET
- Models in C or C++
- Interpreted Java
A hotspot is a part of the code that takes significant time to run, a bottleneck for an algorithm’s performance. The decomposition of the legacy software application code would help identify software module that have a high hotspot probability factor which then would lead to increased focus on further computational resources dedicated to applied optimization techniques.
2.3 Optimization Techniques without Explicit Parallelism
Analysis will establish target gains to be achieved using parallelism. The analysis is guided by established theoretical backing such as Amdahl’s Law. Where parallelism has reached its peak performance gains this effort will then provide guidance to techniques beyond parallelism for increased gains.
The process of generating parallel code form the serial code comes with some risks that must be managed by the solution. Parallel techniques typically split serial code to a pool of worker threads, each operating independently, which then run to completion until the end of a parallel section. When processing is threaded across multiple cores, attention must be paid by the analyzer to data conflicts, race conditions, priority inversions or deadlocks. A post-parallelization is performed after the analysis/optimization stage. There are COTS tools such as Intel Advisor XP as described in paragraph 2.4.1.10 that can also be used in parallel with the S2P+ tool to mitigate the risks associated with parallelism.
With a task/thread pool, the outcome depends on the relative timing of multiple tasks, and race condition can occur. The piece of code containing the concurrency issue is called a critical region. Typically when multiple threads are utilized to access common data, for data consistency, a mutex or lock is utilized to protect access to thread shared data. The use of locks brings inherent risk in a multithread environment which is familiar to developers of real time systems and embedded applications. Solutions such as mutexes with priority inheritance/ceilings are available on certain platforms to avoid conditions such as priority inversions [2]. We have utilized non-blocking techniques in our own optimized parallel solutions to avoid these common multithreaded risks by using alternatives to locking mechanisms. These non-blocking techniques may be applied to the S2P+ to avoid concurrency issues associated with parallelism.
The following paragraphs describe additional code optimization techniques for performance that we propose for a broad optimization solution in addition to serial to parallel conversion techniques. These techniques do not perform explicit serial to parallel code conversion, and therefore avoid concurrency issues.
2.3.1 Promotion to 64-bit Native Code
One area that provides direct benefit to a 32-bit legacy application for execution on a 64-bit operating system platform such as Windows 7/8 is to convert the 32-bit application code into 64-bit code. Applications developed for 32-bit operation are run on 64-bit Windows operating systems using the WoW64 (Windows 32-bit on Windows 64-bit) subsystem. Since no structural changes to occur to the legacy code, there is a low risk of introducing concurrency based issues.
2.3.1.1 64-bit Performance Gains
After being recompiled for a 64-bit system a program can potentially use huge amounts of memory (192 GB for Windows 7, 512 GB for Windows 8 Pro/Enterprise) and its speed may increase in 5-15%. 5-10% of speed gain is achieved due to architectural features of the 64-bit processor, for example, a larger number of registers. And another 1-5% performance gain is determined by the absence of the WoW64 layer that translates calls between 32-bit applications and the 64-bit operating system.
For example, Adobe reports that a 64-bit version of Photoshop executes 12% faster than its 32-bit version equivalent release. Generally, operations run approximately 8-12% faster. An advantage of using the 64-bit version of Photoshop CS5 is to access amounts of RAM beyond what Photoshop can access as a 32-bit application for platforms which are configured for more than 4 GB of memory.
2.3.1.2 64-bit Migration Techniques
Migrating code from 32-bits to 64-bits, similar to serial to parallel techniques, are development language specific. The following paragraphs describe migration procedures for various development languages.
2.3.1.2.1 C/C++ Language
Migration of source code modules developed in either ‘C’ or ‘C++’ could be a simple as rebuilding the modules in the compiler specifying a 64-bit target. MSVS provides support for detecting 64-bit conversion issues with the ‘/Wp64’ compiler option. This compile option will test variables of the type int, long, and pointer for compliance with 64-bit operation. COTS software tools such as PVS-Studio [3] are available to perform static analysis on legacy code to detect 32-bit to 64-bit migration issues. Lint can be leveraged to identify suspicious and non-portable constructs as part of static code analysis to further ensure the legacy code is platform architecture neutral.
2.3.1.3 C#/VB.NET Managed Code Languages
In general, conversion of 32-bit managed code (C# or VB.NET) applications to 64-bits should not be problematic. Managed code normally is converted to an intermediate language (IL) and that is processor independent and works on 32 and 64 bit platforms.
2.3.1.3.1 3rd Party Libraries
When decomposing a legacy project into language and functional modules, part of that effort is to identify 3rd party libraries provided without source code that are utilized as part of the project. When converting 3rd party libraries or components to 64-bits, it may be determined if there are 64-bit versions available. If not, alternative means are necessary similar to the descriptions in later paragraphs.
2.3.1.3.2 Optimized Compilers
While the MSVS compiler provides a range of performance optimizations, it is not necessarily optimized to take advantage of multi-core processors and architectures for C/C++ development. The Intel C++ Compiler version 2013, also known as icc or icl, is a group of C/C++ compilers from Intel Corporation available for Apple Mac OS X, Linux and Microsoft Windows. This compiler integrates into MSVS 2005, 2008, and 2010 and is part of Intel Parallel Studio XE [6] and Intel C++ Studio XE 2013 [7]. The compiler is supported on IA-32 and Intel 64 architectures, and some of the optimizations made by the compiler are targeted towards Intel hardware platforms. This puts a constraint on the platform where the legacy applications are runtime evaluated for performance to execute as Intel based laptops, desktops, or servers.
The auto-parallelization feature of the Intel C++ Compiler automatically translates serial portions of the input program into semantically equivalent multi-threaded code. This is referred to in this document as implicit parallelization and occurs without changes to the legacy application source code. Automatic parallelization determines the loops that are good work sharing candidates, performs the data-flow analysis to verify correct parallel execution, and partitions the data for threaded code generation as is needed in programming with OpenMP [15] directives. The OpenMP [15] and auto-parallelization applications provide the performance gains from shared memory on multiprocessor systems.
Intel is also the author of the Intel Cilk Plus [12], Intel Thread Building Blocks (TBB) [10], and Intel Advisor XE 2013 [14] parallel technologies as described in paragraph 2.4.1. In managed code, the Just-In-Time (JIT) compiler in the runtime does nearly all the optimization.
2.3.1.3.3 SIMD and Vectorization
Many general-purpose microprocessors today feature multimedia extensions that support SIMD (single-instruction-multiple-data) parallelism on relatively short vectors. SIMD has been available on mainstream processors such as Intel’s MMX, SSE, SSE2, SSE3, Motorola’s (or IBM’s) Altivec and AMD’s 3DNow. SIMD intrinsics are primitive functions to parallelize data processing on the CPU register level. By processing multiple data elements in parallel, these extensions provide a convenient way to utilize data parallelism in scientific, engineering, or graphical applications that apply a single operation to all elements in a data set, such as a vector or matrix.
Vectorization is a form of data-parallel programming. In this, the processor performs the same operation simultaneously on N data elements of a vector (a one-dimensional array of scalar data objects such as floating point objects, integers, or double precision floating point objects).
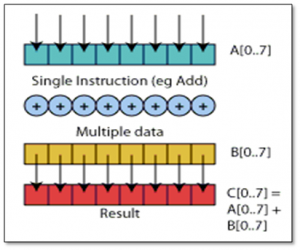
Figure 3: SIMD Model
The Intel C++/Fortran compiler supports auto-vectorization, automatically taking advantage of the multimedia extensions built into the processor. Details on vectorization using the Intel compiler are described by the citations [8] and [9].
2.4 Parallel Solutions
A trade study of automatic serial-to-parallel techniques and solutions will be performed under this effort. This section covers current areas of interest for the study. One part of the study will be the ways to divide an application over multiple processing cores by finding a means to automatically parallelize the sequential code. This is an active area of research and one of core areas in the solution space of this technology. Parallel solutions are language dependent. No one technology is currently available for various development languages (in managed or unmanaged code). The C++ language is the more traditional native code language used for high performance based implementations. In contrast, C#, VB.NET, and Java are more suitable for lower performance GUI components. The following paragraphs describe the open source parallel technologies available in different development languages. These technologies will form the underlying basis, or toolset, for the S2P+ application generated code as described in paragraph 2.5.1.3.
The specific parallel technology used is development language specific and will be selected based on an evaluation of suitability to task based on the legacy application to be converted and the development language where the hotspots exist. The initial focus of the S2P+ application will be for simulation models coded in C and C++, many of which were converted from MATLAB code conversion.
2.4.1 Parallel Solutions for C/C++
The C/C++ development languages are the hotbed languages where focused effort in parallel development is currently being performed. There is a wealth of resources available for converting serial application code to parallel implementations as described in the following paragraphs. MDA’s BMDS enterprise-level simulation models coded in C or C++ will be the principle focus of the S2P+ application.
2.4.1.1 OpenMP
OpenMP [15] is an open source project that supports multi-platform shared-memory parallel programming in C/C++ and Fortran as shown in the Figure 4. The OpenMP [15] API defines a portable, scalable model with a simple and flexible interface for developing parallel applications on platforms from the desktop to the supercomputer.
Figure 4: OpenMP Model
OpenMP follows the fork/join model as shown in Figure 5:
- OpenMP programs start with a single thread; the master thread (Thread #0)
- At the start of the parallel region, the master thread creates a team of parallel ”worker” threads (FORK)
- Statements in the parallel block are then executed in parallel by every worker thread
- At the end of parallel region, all threads synchronize, and join the master thread (JOIN)
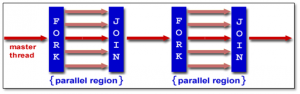
Figure 5: OpenMP Fork Join Model
On the Windows platform, OpenMP directives are preceded with a #pragma construct which allows the original source code to remain unchanged. This is an important consideration when trying to achieve the goal of minimizing changes to legacy source code change to preserve as much as possible validation to the existing algorithms.
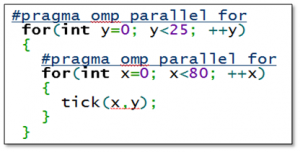
Figure 6: OpenMP Sample
Rather than a library, the OpenMP standard is implemented and depends upon the compiler. The MSVS compiler only supports OpenMP v2.0, which omits some very useful enhancements to the OpenMP standard in version 3.1. This includes the omission of a task yield API to prevent busy waits on the worker threads and atomic operations [16]. As result, it is recommended that the Intel C++ compiler described in paragraph 2.3.1.3.2 be used for legacy code as it supports OpenMP v3.1.
The pros and cons of OpenMP are summarized at the referenced citation [17]. OpenMP-compliant implementations are not required to check for data dependencies, data conflicts, race conditions or deadlocks; any of which may occur in conforming programs. In addition, compliant implementations are not required to check for code sequences that cause a program to be classified as non-OpenMP API conforming. Application developers are responsible for correctly using the OpenMP API to produce a conforming program.
What makes OpenMP particularly attractive is the simplicity of the range of statements, and the unified code for both serial and parallel applications allows OpenMP constructs to be treated as comments when sequential compilers are used. OpenMP is a technology which has minimal impact to the existing legacy source code perhaps preserving the validation of the legacy code.
PVS-Studio [3] provides static analysis tools for verifying OpenMP compliant, detecting some errors causing race conditions, ineffective use of processor time and so on. The static analyzer works with the source code and reviews all the possible ways of program execution, so it can find some of these very rare errors.
2.4.1.2 OpenCL
Open Computing Language (OpenCL) [19] is a framework for writing programs that execute across heterogeneous platforms consisting of central processing units (CPUs), graphics processing units (GPUs), digital signal processors (DSPs) and other processors. OpenCL includes a language (based on C99) for writing kernels (functions that execute on OpenCL devices), plus application programming interfaces (APIs) that are used to define and then control the platforms. OpenCL provides parallel computing using task-based and data-based parallelism. OpenCL is an open standard maintained by the non-profit technology consortium Khronos Group. It has been adopted by Apple, Intel, Qualcomm, Advanced Micro Devices (AMD), Nvidia, Altera, Samsung, Vivante and ARM Holdings. To utilize OpenCL, the GPU on the graphics card or the CPU of the target system must support the OpenCL parallel programming language and the OpenGL [20] rendering language. Therefore, OpenCL is not entirely platform independent.
2.4.1.3 OpenMPC
General-Purpose Graphics Processing Units (GPGPUs) have emerged as promising building blocks for high-performance computing with higher throughput and performance than traditional CPUs. Depending upon the hardware platform selected, a GPU may exist as a resource to exploit. In general, GPU programming complexity poses a significant challenge for developers. To improve the programmability of GPUs for general purpose computing, the CUDA (Compute Unified Device Architecture) programming model [21] has been introduced. For the S2P+ application, depending upon the existence of a GPU on the hardware platform, the code generation could take advantage of research being performed in the areas of GPU programming. For example, the OpenMPC [22] initiative proposes an API for improved CUDA programming providing programmers with a high level abstraction of the CUDA programming model, in essence providing OpenMP-to-CUDA translation and optimization. CUDA is more directly connected to the platform upon which it will be executing because it is limited to Nvidia GPU hardware.
2.4.1.4 Intel Thread Building Blocks
Intel Threading Building Blocks (TBB) is a runtime-based parallel programming model for C++ code that uses threads. It consists of a template-based runtime library to help you harness the latent performance of multi-core processors. TBB [10] has been the most popular library solution for parallelism for C++. It is not available for managed code or Java. TBB was leveraged on the iNET Link Manager real time software in support of a contract with the Navy as described in paragraph 3. TBB is a library that assists in the application of multi-core performance enhancement techniques. Often improvements in performance for multi-core processors are achieved by implementing a few key points. There are a variety of approaches to parallel programming, ranging from using platform-dependent threading primitives to new languages. The advantage of TBB is that it works at a higher level than raw threads, yet does not require exotic languages or compilers. You can use it with any compiler supporting ISO C++, including MSVS.
The library differs from typical threading packages in the following ways:
- Allows specification of logical parallelism instead of threads
- Targets threading for performance
- Provides compatibly with other threading packages
- Emphasizes data parallel programming which is scalable
- Leverages generic programming
TBB provides a host of tools for the C++ programmer to leverage when writing parallel code. Chiefly these include:
- Loop Parallelization Constructs (similar to OpenMP)
- Concurrent Data Structures
- Locks of Various Flavors
- Access to Low-Level Hardware Primitives
- Task Based Programming
Intel TBB has been designed to be more conducive to application parallelization on client platforms such as laptops and desktops, going beyond data parallelism to be suitable for programs with nested parallelism, irregular parallelism and task parallelism.
2.4.1.5 Intel Cilk Plus
Intel Cilk Plus [12] is an extension to the C and C++ languages to support data and task parallelism. Essentially it is a product with a very simple APIs similar to OpenMP. The concepts behind Cilk Plus are simplification of adding parallelism.
Intel Cilk Plus offers a quick and easy way to harness the power of both multi-core and vector processing. The three Intel Cilk Plus keywords (cilk_spawn, cilk_sync, cilk_for) provide a simple yet powerful model for parallel programming, while runtime and template libraries offer a well-tuned environment for building parallel applications. Cilk Plus contains data reducers as C++ templates to allow for lock free access to thread shared data and to efficiently avoid data race conditions and concurrency issues.
Array Notations is an Intel-specific language extension that is a part of Intel Cilk Plus feature supported by the Intel C++ Compiler that provides ways to express data parallel operation on ordinary declared C/C++ arrays [13]. With the use of array notations application performance can be increased through vectorization as described in paragraph 2.3.1.3.3.
2.4.1.6 OpenMP comparison to TBB
For a technical comparison between OpenMP, Intel TBB and Windows threads, refer to citation [11]. In general, TBB is more C++ like than OpenMP. TBB will require more time consuming changes to the original code base with a potentially higher payoff in performance and features, while OpenMP gives a quicker payoff.
Choosing threading approach is an important part of the parallel application design process. There is no single solution that fits all needs and development languages. Some require compiler support. Some are not portable or are not supported by the specialized threading analysis tools. TBB covers commonly used parallel design patterns and helps create scalable programs faster by providing concurrent data containers, synchronization primitives, parallel algorithms, and a scalable memory allocator.
OpenMP lacks some of the features of TBB, but is simpler to implement and therefore may be more applicable to the S2P+ development for generating parallel code from legacy serial code. OpenMP (or OpenMPC) are likely to have less impact to the original source code and therefore preserve the independent verification and validation (IV&V) to the legacy code models.
2.4.1.7 Co-existence of OpenMP and TBB
TBB, OpenMP, and native threads can co-exist and interoperate. However, processor oversubscription is possible because TBB and OpenMP run-time libraries create separate thread pools; by default each creates a number of threads that matches the number of cores on the platform. Oversubscription is contention for processing units that can lead to loss of efficiency. Both sets of worker threads are used for compute intensive work and processor oversubscription can result. Therefore, the S2P+ application will likely leverage a uniform threading model as Intel TBB, Intel Cilk, or OpenMP, perhaps selectable by the operator during the code generation process.
2.4.1.8 OpenMP comparison to Cilk Plus
OpenMP and Intel Cilk Plus are two frameworks that allow a programmer to express parallelism using a very simple syntax. Both of these technologies rely on similar ideas. There are source coding patterns that indicate where parallelism can be applied. There is a pool of worker threads that can be dynamically applied to work units. Generally speaking, the number of worker threads in the pool is determined by the number of physical processing units available.
Ideally Intel Cilk Plus and OpenMP should share the same pool of threads. If they don’t, then this creates the possibility of over subscription. Generally speaking, both Intel Cilk Plus and OpenMP take care to avoid over subscription, but this only works if the two threading subsystems are aware of each other or at least are not simultaneously active.
We will evaluate the various technologies to determine suitability to task in the development of the S2P+ application. Both of these frameworks are light weight in terms of added code to support parallelism, with OpenMP using #pragma compiler directives and Intel Cilk Plus using C/C++ APIs.
2.4.1.9 Message Passing Interface (MPI)
Message Passing Interface (MPI) [18] is a standardized and portable message-passing system designed by a group of researchers from academia and industry to function on a wide variety of parallel computers. The standard defines the syntax and semantics of a core of library routines useful to a wide range of users writing portable message-passing programs in Fortran or the C programming language. MPI is most suited for a system with multiple processors and multiple memories (e.g. a cluster of computers with their own local memory). You can use MPI to divide workload across this cluster, and merge the result when it is finished. While MPI is discussed as a solution in the parallel community, and is applicable to a simulation environment of distributing work to a network of computers, the primary focus of SP2+ is for operation on a single shared memory laptop running simulation models. Therefore OpenMP, OpenMPC, Intel TBB, or Intel Cilk Plus is more appropriate than MPI.
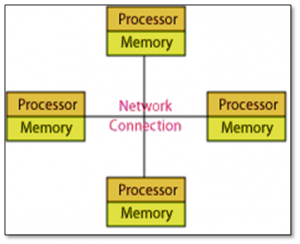
Figure 7: MPI Model
2.4.1.10 Intel Advisor XE 2013
As part of the Intel C++ compiler frameworks, Intel Advisor XE [14] is an application whose purpose is to enable developers to evaluate parallelization of legacy code. While Advisor XE does not actually generate parallel code from serial code, it is a modeling tool which is used to evaluate legacy code, and determine the benefits in performance of parallelism. In summary, Intel Advisor XE provides:
- Manual HTL (human-in-the-loop) productivity boosting parallelism modeling tool
- A methodology and set of tools to help you easily add correct and effective parallelism to your program
- Assists in the parallelization of software with confidence by providing verification of no side effects
- Is targeted for C/C++/Fortran on Windows/Linux and C# .NET on Windows platforms
Intel Advisor XE 2013’s workflow panel guides you through the steps to successfully add effective threading to your application. Implementation is delayed until step 5. This lets you use the active code base and continue to release product updates during the design phase (steps 1-4). The Intel Advisor XE product provides man in the loop parallelization. The workflow is shown in Figure 8.

Figure 8: Product Workflow
It is anticipated that Intel Advisor XE will provide an essential modeling element for the development of the S2P+ application, helping to identify parallel patterns in source code, measuring the results of the parallelism, verifying implemented code contains no concurrency issues, and evaluating the performance of the various parallel programming models. Note that the performance analysis results using Intel Advisor XE is based on the hardware platform where the application runs; so higher fidelity is achieved by analyzing the legacy code on a hardware platform similar to what will be deployed.
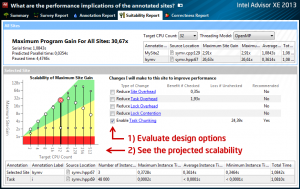
Figure 9: Intel Advisor XE Suitability Report
2.4.2 Parallel Solutions for Unmanaged Visual Basic
OpenMP is not available for unmanaged applications or components written in Visual Basic (VB). However, VB can access C++ and C based DLLs, so notionally native code products like Intel TBB and Intel Cilk Plus should be available. Neither of these two products provides COM/OLE/ActiveX interfaces for use.
2.4.3 Parallel Solutions for Managed Code (C# and VB.NET)
There is no direct support for OpenMP, TBB, or Intel Cilk Plus in managed code. Instead managed code provides support for adding parallelism and concurrency to applications via the Thread Parallel Library (TPL) [24] and the Parallel LINQ (PLINQ) [25] available only for the .NET framework version 4.0 and greater as shown in the .NET framework stack in Figure 10.
Prior to .NET 4.0, it was difficult to develop applications capable of taking full advantage of multi-core microprocessors. It was necessary to launch, control, manage, and synchronize multiple threads using complex structures that were capable of handling some concurrency but not the modern multi-core systems.
Supporting data parallelism, task parallelism, and pipelining, the TPL provides a lightweight framework to enable developers to work with different parallelism scenarios, implementing task-based designs instead of working with heavyweight and complex threads.
The primary purpose of PLINQ is to speed up the execution of LINQ to Objects queries by executing the query delegates in parallel on multi-core computers. PLINQ performs best when the processing of each element in a source collection is independent, with no shared state involved among the individual delegates. To achieve optimum performance in a PLINQ query, the goal is to maximize the parts that are parallel and minimize the parts that require overhead.
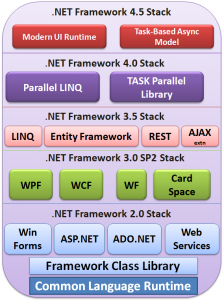
Figure 10: The .NET Framework Stack
To utilize these parallel libraries for legacy managed code applications, legacy applications would need to be converted to support the .NET framework version 4.0 or greater. In concept, this should not be that difficult a process requiring significant legacy code rework, and would simply require rebuilding the managed code applications targeting the more recent .NET framework. When converting legacy managed code application code to support parallelism, the S2P+ application would generate application code using the TBL [24] and PLINQ .NET [25] library APIs.
2.4.3.1.1 MPI.NET
While MPI is for distributed systems, OpenMP is shared memory on a desktop. MPI.NET [23] is a high-performance, easy-to-use implementation of the Message Passing Interface (MPI) for Microsoft’s .NET environment. MPI is the de facto standard for writing parallel programs running on a distributed memory system, such as a compute cluster. The MPI.NET project became inactive in 2008.
2.4.4 Parallel Solutions for Java
Similar to C#, there is no direct support for OpenMP or Intel Thread Building Blocks or Cilk Plus in Java. Instead Java has a number of development options for converting Java code to support parallel processing.
JOMP is a research project whose goal is to define and implement an OpenMP-like set of directives and library routines for shared memory parallel programming in Java [26].
JPPF makes it easy to parallelize computationally intensive tasks and execute them on a Grid [27]. Pyjama [28] is an active research project and it aims at supporting OpenMP-like directives for Java. Pyjama follows the OpenMP philosophy and its shared memory fork-join model. Pyjama also supports the GUI-awareness for its use in the development of interactive applications. Programming in Pyjama integrates the benefits of using the directives based incremental parallelism with the high level object oriented programming, in this case Java. Thus, when working in Java, the Pyjama directives can be used to add expressive parallelism and concurrency, without the need to introduce major restructuring or reimplementation. The salient features of Pyjama include:
- Conventional OpenMP-like directives for parallelism in Java.
- GUI-aware directives for the application development.
- Incremental concurrency through the GUI-aware directives.
- Support for the Android platform.
It is also possible to just use threads and the in-built concurrency constructs to achieve parallelism in Java [29].
2.5 Explicit Parallelization via S2P+
This section describes the S2P+ application, the system design goals, the workflow, and the technical implementation details of the S2P+ application. S2P+ will utilize an underlying technology such as OpenMP as described in the previous paragraphs as the underlying toolset for building the source code to source code conversion.
Automatic or semi-automatic conversion of serial code into its functionally equivalent parallel version remains an open challenge for researchers for the past decade. Many researchers from academia and industry have been working towards such automatic parallelization tool. These tools can transform legacy serial code into a parallel code to execute on parallel architectures.
Though there are few tools that perform this task, the industry is still in search of a tool that will give optimum performance improvement for variety of programs. The major challenges involved in design and implementation of such a tool include finding alias variables, dependency between statements, side-effects of function calls, etc. Additionally, the tool has to deal with the variety in coding styles and development languages.
For the development of the S2P+ application, we will leverage existing research on automatic parallelization. There is a number of automatic parallelization tools present related to Fortran and C languages. These include S2P [30], Cetus [31], and Pluto [32], CAPTools/CAPO [33] [34], ParaWise [35], and AutoFutures [36]. There are also open source compilers whose ambitions are similar to the Intel C++ compiler in terms of automatically translating serial portions of the input program into semantically equivalent multi-threaded code.
These applications are not yet directly applicable because of the following:
- Support source code only in ‘C’ or Fortran (no support for C++/C#/Java/VB.NET)
- Have Linux rather than Windows underpinnings
- Are research rather than production caliber efforts
- Are a commercial product (ParaWise) and not open source
2.5.1 Functional vs. Data Parallelism and Threading Models
One consideration in parallelism is how to decompose the work in an application to enable dividing the task between the different processor cores. There are two categories of decomposition summarized as follows:
- Functional decomposition – division based upon the type of work
- Data decomposition – division based upon the data needing processing
Functional decomposition attempts to find parallelism between independent steps in your application. As long as each step is an independent task, it is possible to apply functional decomposition and execute each step concurrently. Functional decomposition is typically implemented using explicit threading models, such as library based threads.
Data decomposition involves finding parallelism between data items. For example, an image processing or simulation algorithm is an example of data decomposition, where each image (the data) could be processed independently of the other images.
In general, it is easier to scale applications with data decomposition as opposed to functional decomposition.
There are several techniques in use today to thread applications: library-based and compiler-based threading. Examples of library-based threading include Windows Thread API and POSIX threads. Examples of compiler-based threading are OpenMP and the technologies described in section 2.4.
Library-based threading technologies are explicit in that the developer is responsible for explicitly creating, controlling, and destroying the threads via function calls. Explicit threading tends to be more flexible than compiler-based threading in adapting to the particular needs required to parallelize an application. Explicit threading can parallelize all of the same applications that compiler-based threading can handle and more. Explicit threading tends to be more difficult to use than compiler-based threading, and is significantly more invasive to the original source code. Explicit threading can utilize thread priorities and thread affinities to provide for setting thread priorities relative to other application and operating system threads, and CPU shielding, the process of isolating and pinning worker threads to hardware cores.
In compiler-based threading, the compiler handles threading of the application with input from the user coming from language directives. Explicit threading can perform both functional and data decomposition whereas compiler-based threading is more suited for data decomposition. Explicit threading models such as POSIX have been ported to several operating systems. The availability of compiler-based threading is dependent on compiler support and the underlying threading support.
All of the underlying tools described in section 2.4, which will form the underpinning of the source code generated by the S2P+ application, utilize compiler-based threading as the technology. Compiler based threading typically creates a thread pool of worker threads, usually one thread per hardware core, which implement the fork-join model as shown in Figure 5. Compiler based threading does not support setting worker thread priorities or affinities as used with CPU isolation. While OpenCL supports both data and task parallelism, the most efficient model for GPU execution is data parallelism by dividing the work into parallel operating work items.
To take advantage of compiler-based threading, the S2P+ application will need to identify regions in the legacy code where data rather than functional parallelism exist. The application will look for signatures in the legacy code, such as matrix, array, or vector operations, to identify regions that will benefit from compiler based threading and data decomposition. A particular area of focus for the S2P+ is the conversion of legacy models whose origins are automatically converted code whose origin is MATLAB. The S2P+ application will look for algorithmic patterns to identify regions for data decomposition for parallel operation.
2.5.1.1 Detecting Parallelism
The first step in the parallelization process is to determine regions of the legacy code that would benefit from parallelization. This may be performed via a static analysis of the legacy code, or dynamically using runtime analysis of the running application to identify the application hotspots. The ideal solution may combine information from both static and dynamic analysis. Since parallelization of regions of source code inherently comes with some performance overhead, a technical challenge associated with parallelization is to identify parallel regions such that the performance gain exceeds the parallelization overhead.

Figure 11: General Method for Detecting Parallelism
2.5.1.1.1 Static Analysis
Static program analysis is the analysis of the legacy computer software extracting out sections that may benefit from parallelism that is performed without actually executing programs. This is the first stage where the application will read the input source files, possibly identified by a MSVS project file, to identify all static and extern usages. Each line in the source file will be checked against pre-defined patterns to segregate into tokens. These tokens will be stored and will be used later by the grammar engine. The grammar engine will check patterns of tokens that match with pre-defined rules to identify variables, loops, controls statements, functions, etc. in the code. S2P+ may utilize open source tools as part of the static analysis including Yacc [38] & Bison [39] for scanning and parsing the application source code.
2.5.1.1.2 Dynamic Analysis
The dynamic analysis is similar in goals to the technique used by the Intel Advisor XE [14] application in the “Survey” step as described in paragraph 2.4.1.10. For the S2P+ application to perform dynamic analysis of the application, the legacy application would need to be run on a representative platform with all necessary inputs to drive the application. S2P+ may leverage open source tools for dynamic analysis such as Valgrind [40] as a means of capturing profile information on the legacy application to identify hotspots for parallelization. The profiler might be built directly into the S2P+ application.
2.5.1.2 Analyzer
The analyzer is used to identify sections of code that can be executed concurrently. The analyzer uses the data information provided by the scanner-parser or dynamic analyzer. The analyzer will first find out all the functions that are totally independent of each other and mark them as individual tasks. The analyzer then finds which tasks have dependencies.
2.5.1.3 Code Generation
The S2P+ application will create new source code and thus allows the original source code of the application to remain unchanged. The code generation process will generate content based on the source code development language of the original file (e.g. C/C++/C#/VB.NET/Java) and the active/selected parallel programming model (e.g. OpenMP, OpenMPC, TBB, Cilk Plus, TPL). Based on an evaluation of the legacy code to be converted as well as evaluating the target hardware platform and parallel performance, a single parallel programming model (e.g. OpenMP) may initially be supported during the code generation procedure. The goal of the code conversion procedure is to generate application code which is platform neutral. The underlying technology utilized in the generated source code will query the capabilities of the executing platform and utilize the detected resources (e.g. the total number of CPUs, GPUs, and number of cores on each device). OpenMP is platform neutral and has the smallest footprint when converting legacy code and attempting to preserve legacy validation of algorithms.
3 Related Work
We have experience on several previous programs similar to the ambitions of S2P+. Our company consists of engineers who have spent decades working on Windows and Linux desktop applications, and real time embedded systems; so we fully understand Windows platform development, parallel development for multi-core platforms, and the requirements of both desktop and embedded systems development. We have decades of commercial Windows platform development that range from 16/32/64-bit developments in ‘C’ using the Microsoft SDK, C++ development using the MFC, OLE/COM/ActiveX, Visual Basic, Qt for cross platform development, as well as managed code in C#.NET and VB.NET. We have domain knowledge for Windows platform development as well as Linux and embedded systems. We utilize and have extensive experience with the OPNET communications simulation environment, and it is an integral part of our development workflow for both embedded and desktop communications applications.
For the current iNET program, we are solely responsible for the design, development, and deployment of the Link Manager for the Central T&E Investment Program (CTEIP). The iNET Link Manager is implemented as a daemon operating on the Linux desktop platform responsible for providing centralized quality of service (QoS) based TDMA scheduling control of an RF network of radios. The Link Manager is coded to support the cross platforms of Windows and Linux, but has become primarily focused on Linux due to the advantages the Linux kernel provides for real time application execution.
The Link Manager, to achieve its real time deadlines (50 ms scheduling), utilizes both multithreading and multi-core approaches to exploit the concurrency in its computational workload. It operates on a Dell R620 server platform with two separate processors, each with 6 physical cores, 12 logical cores utilizing hyper-threading, for a total of 24 accessible cores.
To provide for 24×7 100% reliable scheduling, the Link Manager platform benefits from performance tuning. Performance tuning of the Link Manager platform consists of run time CPU shielding, a practice where on a multiprocessor system or on a CPU(s) with multiple cores, real-time tasks can run on one CPU or core while non-real-time tasks run on others, and real time thread priorities for application threads are used with the Linux scheduler. Changes are made runtime by the Link Manager based on thread priorities and CPU cores available on the hardware platform. As described in paragraph 2.5.1, the Link Manager utilizes library or explicit threading by task/functional rather than data decomposition.
The Link Manager utilizes the Intel TBB [10] concurrency collections in the implementation for creating table content which is concurrently accessed from a thin client interface, secondary threads, and a custom binary messaging protocol to an upstream controller. The TBB concurrency collections are non-locking thread safe collections (equivalent to STL collections in APIs) but avoid locking and therefore multi-threaded concurrency issues (priority inversions, deadlocks, live locks, convoying, etc.). The TBB scheduler itself was not used for the Link Manager as it does not currently support either real time thread priorities for the worker threads in the pool, nor thread affinities for CPU pinning and isolation. This work was performed for CTEIP, and is complete.
As part for the Link Manager development, we developed two custom visualization tools to support the development, use, monitoring, testing, and maintenance of the application.
To support viewing of live data, we developed a fat client application in C#.NET that is driven by network packets from a generating application as shown in Figure 12. This technology can be used with any application which needs to generate a spatial view of connected nodes and 2D line graphs.
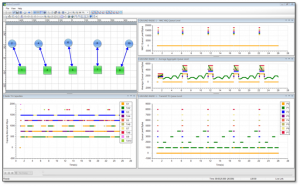
Figure 12: RoboComNV Network Visualizer
The Link Manager is instrumented to generate runtime trace information that is logged into acquisition memory, which is later converted into a Value Change Dump (VCD) [41] file for graphical display of timing relationships. The information logged includes thread duty cycles to log thread efficiencies and timing. Figure 13 shows a sample capture of timing relationships using the open source GTKWave VCD [42] viewer.
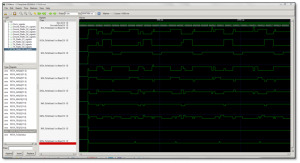
Figure 13: RoboComEV Embedded Visualizer
When developing the trace logger, we were mindful of the observer effect [43], where the act of instrumenting an application for tracing has the potential for changing the behavior of the application itself. To solve this issue, a custom non-locking non-waiting interface was developed to trace acquisition memory to allow multiple threads to generate trace information in a thread safe manner void of potential concurrency issues. This technology can be used with any application which requires insight into thread timing and signal relationships.

Figure 14: Template Based Embedded Systems Source Code Generation
We developed a database table based code generation application which automatically generates embedded ‘C’ code in a target international language for a world leader in the design and manufacture of standard and custom test solutions based. The code generation application is based on user created template files with embedded SQL statements. This application has become an essential productivity tool used by the embedded firmware developers.
4 Related Projects
- Utilized concurrency collections, CPU pinning, and core isolation on multi-core platforms for QoS based TDMA Link Manager for the iNET IP-based advanced flight test telemetry network Central T&E Investment Program (CTEIP).
- Developed MEADS network radio simulation suite for the Linux platform and PPPoE software components for the MEADS embedded network radio.
- Development of a custom application in VBA which generates embedded ‘C’ code using user created template files including embedded SQL statements with a SQL server database backend.
- Development of several commercial highly reliable applications for the Windows platform, mostly client-server architecture with Oracle database back ends for the medical document imaging community.
- Development of a commercial grade a Microsoft Word plug-in for sending very large files over the Internet.
- Development of a commercial ODBC driver for accessing database content stored on IBM mainframes from a Windows client.
5 References
[1] Amdahl’s Law http://home.wlu.edu/~whaleyt/classes/parallel/topics/amdahl.html
[2] Mars Pathfinder Priority Inversion https://www.cs.unc.edu/~anderson/teach/comp790/papers/mars_pathfinder_long_version.html
[3] PVS-Studio https://www.viva64.com/en/pvs-studio
[4] Visual Basic 6.0 to C#.NET http://www.NETcoole.com/vb6tocs.htm
[5] NET to C++ convertor https://www.tangiblesoftwaresolutions.com/Product_Details/VB_to_CPlusPlus_Converter_Details.html
[6] Intel Parallel Studio https://software.intel.com/en-us/intel-parallel-studio-xe
[7] Intel C++ Studio XE 2013 https://software.intel.com/en-us/intel-c-studio-xe-purchase
[8] A Guide to Vectorization with Intel C++ Compilers https://download-software.intel.com/sites/default/files/m/d/4/1/d/8/CompilerAutovectorizationGuide.pdf
[9] Extracting Vector Performance with Intel Compilers https://download-software.intel.com/sites/default/files/article/326586/4.1-cilkplus-vectorization.pdf
[10] Intel Thread Building Blocks https://threadingbuildingblocks.org/
[11] Compare Windows threads, OpenMP, Intel TBB http://software.intel.com/en-us/blogs/2008/12/16/compare-windows-threads-openmp-intel-threading-building-blocks-for-parallel-programming/
[12] Intel Cilk Plus https://cilkplus.org
[13] Getting Started with Intel Cilk Plus Array Notations https://software.intel.com/en-us/articles/getting-started-with-intel-cilk-plus-array-notations .
[14] Intel Advisor XE 2013 https://software.intel.com/en-us/intel-advisor-xe
[15] The OpenMP Project https://openmp.org/wp/
[16] User’s Experience with Parallel Sorting & OpenMP uni-kassel.de/eecs/fileadmin/datas/fb16/Fachgebiete/PLM/Dokumente/Publications_Fohry/sortOpenMP.pdf
[17] OpenMP Pros and Cons https://en.wikipedia.org/wiki/OpenMP
[18] The Open MPI Project: High Performance Message Passing Library https://www.open-mpi.org
[19] The OpenCL Standard https://www.khronos.org/opencl/
[20] The OpenGL Standard https://www.opengl.org/
[21] The CUDA Standard https://developer.nvidia.com/about-cuda
[22] The OpenMPC Project https://ft.ornl.gov/sites/default/files/SC10_LE.pdf
[23] The MPI.NET Project: High-Performance C# Library for Message Passing http://www.crest.iu.edu/research/mpi.net/
[24] Microsoft Thread Parallel Library TPL for .NET http://msdn.microsoft.com/en-us/library/dd460717.aspx
[25] Microsoft Parallel LINQ Library PLINQ for .NET http://msdn.microsoft.com/en-us/library/dd460688.aspx
[26] The JOMP Project for Java http://www2.epcc.ed.ac.uk/computing/research_activities/jomp/index_1.html
[27] The JPPF Project for Java http://www.jppf.org/
[28] The Pyjama Project for Java http://homepages.engineering.auckland.ac.nz/~parallel/ParallelIT/PJ_About.html
[29] The Java Tutorials on Concurrency http://java.sun.com/docs/books/tutorial/essential/concurrency/
[30] The S2P Project http://www.kpitcummins.com/
[31] The CETUS project http://cetus.ecn.purdue.edu
[32] The Pluto Project http://pluto-compiler.sourceforge.NET/
[33] The CAPTools Project http://icl.cs.utk.edu/projects/ptes/PTES_html/CAPTools
[34] Code Parallelization with CAPO http://people.nas.nasa.gov/~hjin/CAPO/index.html
[35] ParaWise for Fortran http://www.parallelsp.com/index.htm
[36] Automatic Parallelization, AutoFutures ipd.kit.edu/Tichy/uploads/publikationen/283/AutoFuturesfinal.pdf
[37] Profiling Java for Parallelism http://www.st.cs.uni-saarland.de/publications/files/hammacher-iwmse-2009.pdf
[38] Yacc http://en.wikipedia.org/wiki/Yacc
[39] Bison http://www.gnu.org/software/bison/
[40] Valgrind for Windows http://sourceforge.NET/projects/valgrind4win/
[41] Value Change Dump http://en.wikipedia.org/wiki/Value_change_dump
[42] The GTKWave Project http://gtkwave.sourceforge.NET/
[43] Observer Effect http://en.wikipedia.org/wiki/Observer_effect_ information_technology